→ Topに戻る
監視対象のホストでNTPサーバーの状況を確認するには、対象にホストにntpdateコマンドがインストールされている必要があります。
自分自身のNTP状態を確認する場合、シェルコマンドでは次のコマンドを実行します。
# /usr/sbin/ntpdate -p 1 -q -o 4 -t 1 -u 33123 127.0.0.1; ret=$?
# echo $ret
このコマンドが正常に実行されると、現在の時刻がNTPサーバーから返されると共に実行結果のステータスとして ret に 0 が返されます。 また失敗した場合には ret の値は 0 以外になります。このコマンドを監視対象のホストで定期的に実行することで、NTPサーバーが正常に動作しているかを検知できるようにします。
(/usr/local/bin/ck_ntpdate.sh)
#!/bin/bash
# -------------------------------------------------
# This command is NTP service available check in local.
# use: ck_ntpdate.sh
#
# Return: =0(Nomal) / !=0(Fail)
# -------------------------------------------------
/usr/sbin/ntpdate -p 1 -q -o 4 -t 1 -u 33123 127.0.0.1 > /dev/null 2>&1 ;ret=$?
echo $ret
作成したスクリプトに実行権限を与えます。 なお、上記スクリプトで"-u 33123"としているのは、デフォルトではntpdateコマンドが送信元ポート番号として123を使うため、Zabbixサーバー自身でNTPサーバーを動作させていた場合にはこのポートがNTPサーバーで使われてしまいntpdateコマンドが実行できないため、明示的に送信ポートを変更しています。
# chmod +x /etc/zabbix/externalscripts/ck_ntpdate.sh
作成したシェルスクリプトを試してみましょう。
# /etc/zabbix/externalscripts/ck_ntpdate.sh
0
NTPサーバーから正常に応答があった場合は 0 が返り、そうでない場合には 0 以外の値は返ってきます。
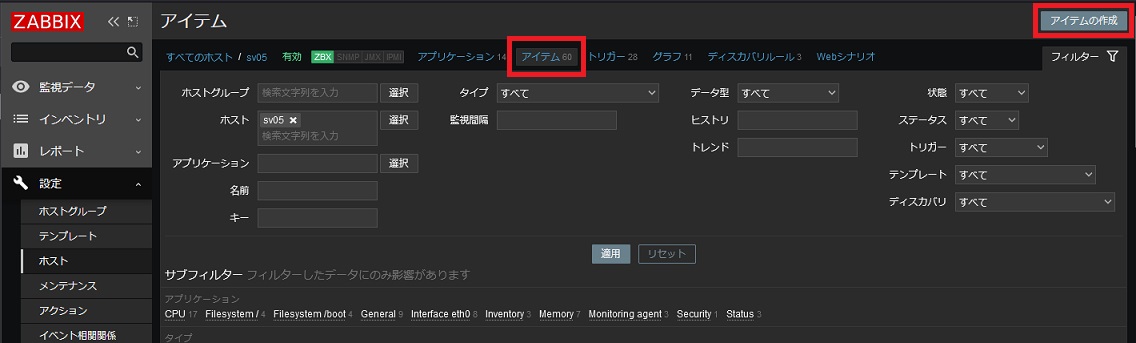
■ 監視アイテム作成
[設定] - [ホスト] から監視対象のサーバを選び、設定画面の [アイテム]タブを開き [アイテムの作成] をクリックします。
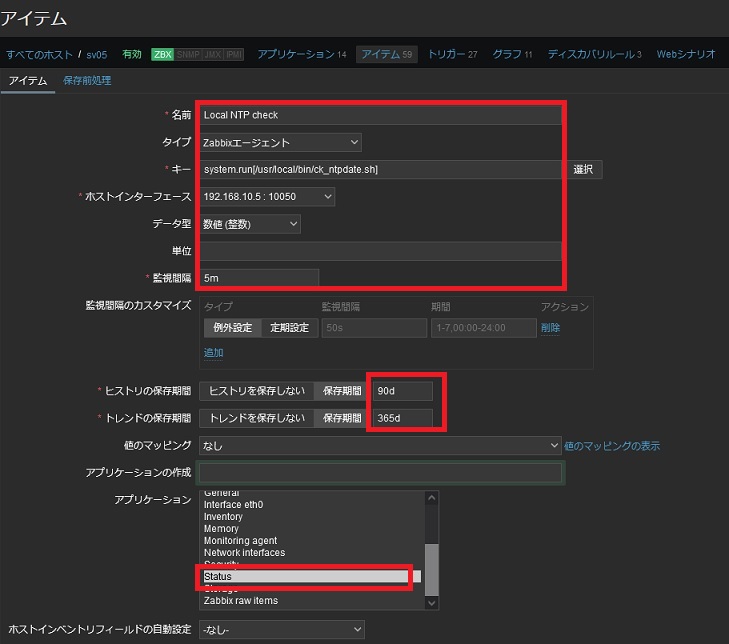
次のようなアイテムを作成します。
- 名前: Local NTP check
- タイプ: Zabbixエージェント
- キー: system.run[/usr/local/bin/ck_ntpdate.sh]
- データ型: 数値(整数)
- 監視間隔: 5m
- ヒストリの保存期間: 90d
- トレンドの保存期間: 365d
- 値のマッピング: なし
- アプリケーション: Status
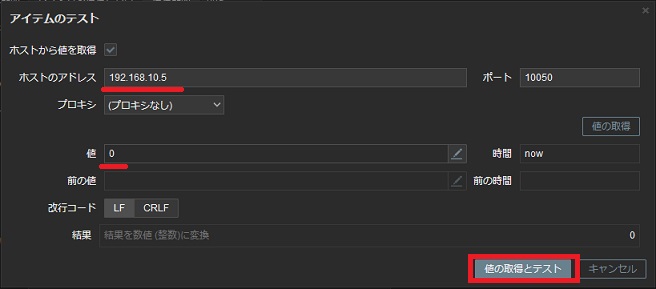
以上を設定したら保存前に[テスト]を実行して値がとれているか確認します。
ホストアドレスには監視対象のホストのIPアドレスが表示されているのを確認し、[値の取得とテスト]を実行すると"値"のフィールドに実行した結果の値が表示されます。
これが問題なければ、[追加]をクリックして内容を保存します。
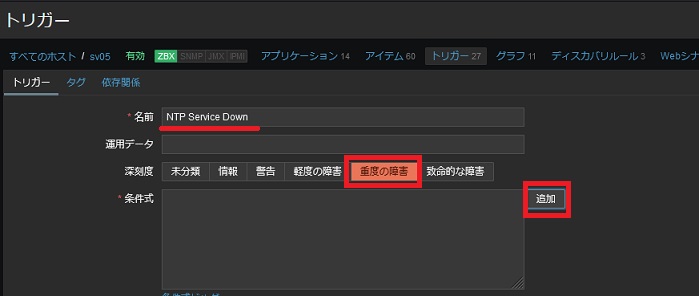
■ トリガーの作成
作成したアイテムによって、定期的にNTPのチェックがされてるようになったなら、この値が変動した時に実行されるトリガーを作っていきます。[トリガー]タブを開き [トリガーの作成] をクリックします。
(1) まず、NTPサーバーに障害が発生したと判断するトリガーを作成します。
- 名前: トリガーの名前 (ex. "NTP server is down")
- 深刻度: この障害の深刻度を定義 (ex. "重度の障害")
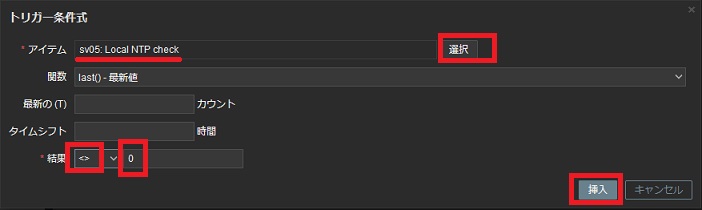
- 条件式: [追加] をクリックして条件式ビルダーを起動する
→ "Local NTP check"アイテムの値が0以外に変化すればこのトリガーが1回だけ発生する
条件式として判定に使うアイテムと、その判定基準を定義します。 ここでは"Local NTP check"というアイテムが0以外だった場合に障害と判定します。
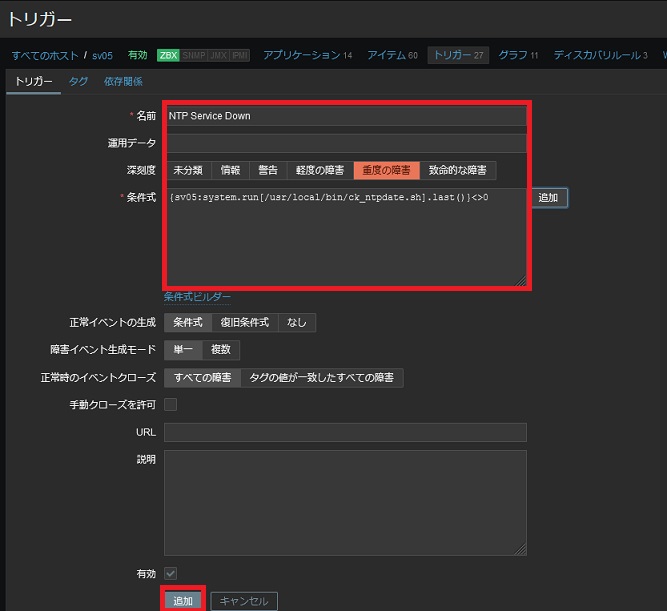
条件式を指定できたら、[追加]をクリックしてトリガーを登録します。 以上で、NTPサーバーに問題がある場合にこのトリガーが"重度の障害"として発生されます。
以上で、NTPの監視設定は完了です。 これで、NTPサービスに障害が発生して何も応答が得られない時には、Zabbixは重度の障害として報告するようになります。
→ Topに戻る