本資料は、Squid を使ったProxyの構築において、可用性を確保するためにロードバランサを使った構成の資料が少ないため作成したものです。 本章を読む前に、「冗長化(HA)への考察」を一読してから本当にロードバランサが必要かを判断することをお勧めします。特に利用数が少人数であるなら pac ファイルを使ったProxyの切り替えも現実的な解と思われます。
ロードバランサは、クライアントからリクエストされたパケットを受け取り、それをバックエンドにある複数のサーバに効率的に転送するための装置です。 例えば、非常にユーザアクセス数の多いショッピングサイトなどでは、見かけ上のWebサーバをロードバランサとしその配下に多数のWebサーバを配置することで大量に発生するリクエストを効率的に処理できるようになっています。
このとき、ロードバランサの重要な機能としてセッション管理があり、同じクライアントからの要求を同じWebサーバに渡すことで、セッション処理が切れないようになっています。この機能が無いと、オンラインショッピング中のカートの中身が消えてしまったり、ログオン状態が中断されてしまう事になってしまいます。
またロードバランサを、Proxy要求を受け付けるフロントに配置することで複数のサーバで構成されたProxyをユーザに単一のProxyに見せかける事ができます。
こうすることで、容易にProxyの性能を上げる事ができるとともに、特定のProxyサーバに障害が発生してもユーザの利用には影響せず、継続してProxyを利用することが可能になります。ただし、ロードバランサ自身に障害が発生すると、バックエンドであるProxyが利用できなくなるため、通常はロードバランサ自身も冗長構成を取ることで継続性を確保します。
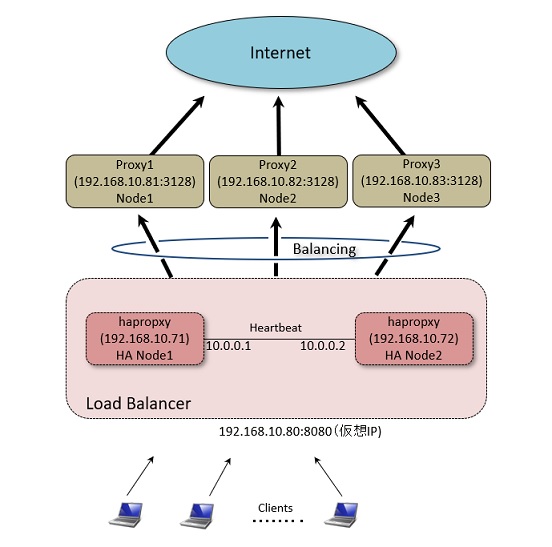
本資料では、以下の図に示す通り複数のProxyサーバのフロントエンドにロードバランサ(HA-Proxy)を冗長構成で配置し、クライアントからのWebアクセスを複数のProxyサーバに分配して処理できるように構成します。 なお、本資料ではProxyについては既に準備済みとして説明を行います。
※注意: F5 のような高価なロードバランサが利用できるのであれば、それらを利用する方が手間がかかりませんのでそれを検討してください。
HAProxy は高信頼性で高速なロードバランサです。HTTPプロトコルによるL7でのバランシングもサポートしており、Webサーバの上位に立てることでWebサーバの隠ぺいを行い、高いリクエスト性能を実現できます。今回はWebサーバでは無く、ProxyのバランシングにHAProxyを使い、Proxyへの負荷負荷分散と経路の冗長化を実現することで高信頼性を確保します。
以下の手順でHAProxyをインストールします。
| 実行コマンド | 実施対象 |
|
$ sudo apt-get update
$ sudo apt-get install haproxy |
HA Node1 HA Node2 |
インストール後、デフォルトの起動設定ファイルを編集し、サービスが起動するようにします。
■ /etc/default/haproxy の修正Debian7を使う場合には、backportsにパッケージがあるので、以下のようにすることでbackportsのパッケージを使うこともできます。 なお、Debian7 の初期パッケージでは以下で説明する Pacemaker が機能しないためOSを含め最新のものを使うようにしてください。 (2014/11/9現在の Linux 3.2.0-4-amd64 、 HAProxy 1.5.6-1 では動作するようです)
以上で、HAProxyの設定は完了です。続いて、ロードバランシングが正しく機能しているか試していきます。
上記の設定を行うことで、"HA Node1"、"HA Node2"ともにロードバランサとして機能するようになっています。ただし、それぞれのHA Propxyの設定においてロードバランサの待ち受けアドレスを"192.168.1.20:8080" としている為に、同時に起動する事はできません。 そこで以下のように1台づつ確認していきます。
(1). 仮想IPを割り当て HA Proxy を起動します。(2). クライアントを使ってWebサイトにアクセスしログを確認ます。
ブラウザの設定で、Proxyとして "192.168.1.20:8080" を指定して、適当なインターネット上のWebサイトにアクセスしてみます。 この結果、Proxy1
~ Proxy3 の各Proxyのアクセスログに、そのサイトへのアクセスした記録が残ります。
ログファイルは、"/var/log/squid/access.log" です。
(3). HAProxyの停止、仮想IPを解放します。
上記までの作業で、"HA Node1"、"HA Node2"の2つのロードバランサの用意ができました。 しかし、このままでは2つのロードバランサの切り替えを手動で行う必要があり、可用性が確保できません。 そこで、システムの冗長化を実現するための Heartbeat というソフトを導入して、2つのロードバランサを稼働系/待機系として構成し通常は稼働系でバランシング処理を行い、稼働系に障害があった場合に待機系に自動で切り替わるようにしていきます。(ここでは"待機系","稼働系"という言葉を使っていますが、以下の設定では主にどちら一方が稼働系に成る訳ではありません。 先に起動したサーバから稼働系となります)
なお従来、Heartbeat は1つのソリューションとして提供されていましたが、現在の Ver.3 からは Heartbeat でハードの監視系を行いソフトの監視は
"Pacemaker" というモジュールで行うようになっています。(詳しくはこちら)
パッケージとしては "heartbeat" をインストールすることで "pacemaker" も一緒にインストールされます。
Heartbeat を利用する場合、相手のサーバの死活監視を行うためのインターコネクトを用意する必要があります。 これはシリアルまたはLANケーブルを利用するもので、通常はLANを利用するのが簡単だと思われます。 必要に応じて、それぞれのHA NodeサーバにLANインターフェースを増設します。 増設したインターフェースが認識できていれば
| 実行コマンド | 実施対象 |
|
$ sudo ifconfig -a
|
HA Node1 HA Node2 |
を実施することで、インターフェースが確認できる筈です。 ここでは、 "eth1" として増設LANボードが認識できているものとして話を進めます。
eth1 のインターフェースに以下のようしてIPアドレスを設定します。
■ /etc/network/interfaces の設定 (HA Node1)
注意として、インターコネクト同士を接続する場合、マシン間にHUBを置かずに直結するようにして下さい。そうしないと、HUBが単一障害点となり冗長化による信頼性が低下します。どうしてもHUBを経由する必要がある場合にはインターコネクト用LANを各マシンで2経路分用意して、それぞれ別のHUBを経由するような工夫をしてください。
以下の手順で Heartbeat をインストールします。
| 実行コマンド | 実施対象 |
|
$ sudo apt-get install heartbeat
|
HA Node1 HA Node2 |
Heartbeat では HA ノード間の接続にマシン名を使用します。 そのため、マシン名(HAノード名)を使ったネットワーク接続が正常に行えるようにしておく必要があります。
現在のマシン名を確認する場合、以下のコマンドを実施します。
| 実行コマンド | 実施対象 |
|
$ uname -n
hanode1 |
HA Node1 HA Node2 |
ここに表示される名前は、/etc/hostname ファイルに定義されています。 この名前を使ってネットワークを接続するには、DNSをきちんと定義するか、/etc/hosts ファイルに名前を登録して必要があります。 ここでは、説明を簡略化するため、/etc/hosts を次のように設定したものとします。
■ /etc/hosts の設定 (HA Node1, HA Node2ともに共通)
ここでの名前は、必ず"uname -n"の結果と合わせてください。 そうしない場合はHeartbeatの起動に失敗します。
Heartbeat を使った場合、HA構成内で動かすサービスは Heartbeat によって起動させる必要があります。 そのため、サービス通常の Init 処理で自動的に起動されないように設定しておく必要があります。今回は、"haproxy"サービスは Heartbeat にて起動されるので、"haproxy"サービスが自動起動しないようにします。
インストール直後は、何も設定ファイルができていないので以下の手順で設定ファイルを所定の場所にコピーします。
注).iptablesを有効にしている場合、ucastで指定するハートビート用インターフェース間の通信ができるようにルールを設定するのを忘れないこと。
Heartbeat プロセスが起動した際に、稼働系で起動するリソースを定義ファイルに定義します。 今回は、仮想IPを割り当てた後に haproxy プロセスを起動するように定義を行います。
■ /etc/ha.d/haresources の設定 (HA Node1)
以上で Heartbeat の設定は完了です。設定にミスがなければ、"HA Node1", "HA Node2"をそれぞれ再起動することで、先に起動できたマシンでHAProxyが動作している筈です。
(起動するまで、少し時間がかかります)
また "sudo ifconfig -a" を実行することで、仮想IPが設定できているかを確認しても良いでしょう。 ここまでの作業で、一応HA構成ができているので稼働系をシャットダウンをするなどで停止すると、待機系でHAProxyが動き出すのを確認できると思います。
残念ながら、この状態でのHA構成は不完全な状態です。 なぜなら Heartbeat だけの HA 構成はサーバのハードウェア障害による待機系への切り替えには成功しますが、HAProxy
ソフトに障害が発生して止まってしまってもそれを検知できないため、待機系への切り替えに失敗します。
これに対処するために、引き続き Pacemaker の設定を行う必要があります。
現在のネットワークの状態の確認は以下のコマンドで確認できます。
Pacemaker では、HA構成となっているプロセスなどを監視するとともに、稼働系で稼働させるリソースの定義を行います。 Debian のデフォルトの Heartbeat では Pacemaker が動作しない状態になっているので、動作するように設定を行います。 設定は簡単で、 ha.cf ファイルに「crm yes」のステートメントを追加するだけです。
/etc/ha.d/ha.cf の設定 (HA Node1, HA Node2 ともに)
この設定後、それぞれのHA Nodeサーバを再起動してみてください。 すると先ほどまで動いていた HAProxy が動かなくなり、また仮想IPも割り当てされなくなる事と思います。
これはリソースの管理が Pacemaker に切り替わったためで正常な動作です。
現在のPacemakerの状態を確認します。
hanode1 と hanode2 が正常に機能していれば、次のようにそれぞれのノードが「Online」となっている筈です。
Pacemakerで監視・起動を行うリソースについて定義していきます。 なお、定義はどちらか一台のHA Nodeで実施します。 実施に当たっては両方の HA Node が Online になっていることを確認してから行ってください。
(1) 基本設定
クラスタ全体の動作に関わる基本的な設定を行います。
STONITH機能が働いていると、この機能をサポートするためのハードが無い状態での以後の設定に不都合なのでこれを無効にします。
また、リソースの状態に問題があった場合の再起動について、リソースの障害が4回発生するとフェイルオーバーし別のサーバに切り替わるように設定を変更します。
(2) 仮想IPに関するリソースを定義
HAProxyサービスを提供する仮想IPを定義します。
この時、以下のグループを実施する前に仮想IPとサービスが別々のノードで動いてしまうことがありますが、グループを設定後に再起動することで正常になる筈です。
設定した仮想IPの確認は、
(3) HAProxy のリソースを定義
HAProxyサービスを定義します。
この設定では、監視・起動用のスクリプトとして "lsb:" すなわち/etc/init.d 以下にある "haproxy" スクリプトを使っています。 "lsb:"スクリプトを使う場合には、その実行時のリターン値として決まった値を Pacemaker が期待しています。 しかし、 Debian では HAProxy 稼働中に再度の起動(Start)を実施した場合の値が求める結果と違うので、これを修正します。
(4) グループの定義
仮想IPとサービスは常に同じサーバで動作させるために group の設定を行います。
(5) ネットワーク監視
サービスを提供するためのLANがネットワーク的に正常であることを確認します。デフォルトゲートウェイ(192.168.1.254)に Ping を実施してLANが正常かを確認するようにします。また、ネットワーク監視はすべてのHA Nodeで行うようにするために、clone設定も実施します。
以上で Pacemaker の設定は完了です。 それぞれの HA Node を再起動して、どちらか一方で HAProxy が正常に動作することを確認してください。 また、Webブラウザの Proxy の設定で "192.168.1.20:8080" を指定して、正常にサイトが表示されることを確認してください。
Pacemaker で設定したリソースを表示する場合には次のように行います。
一部のリソースを削除したいのであれば、
(1) リソースの確認
(2). リソースの停止と削除
を実行します。
Pacemaker で設定したリソースをすべて消去したい場合には次のように行います。
(1) HA Nodeの停止
(2) 設定の消去
(3) HA Nodeのオンライン化
上記の説明で、haproxy のリソース管理(開始、停止、ステータス等)には Linux 標準の init スクリプト(LSB) を使った設定を行っています。
しかし、init スクリプトは必ずしも Pacemaker に最適化された内容ではないために、場合によってはステータスの取り込みに失敗したり、開始や停止に失敗するケースも想定されます。
Pacemaker用のリソース管理には、OCFリソースエージェントを作成して管理する方が望ましいとなっています。 例えば haproxy 用の ocf ファイルは次のように準備します。(Debian7 では以下のOCFリソースエージェントでは正常に動作しないようすのでLSBで実行してください
■ /usr/lib/ocf/resource.d/pacemaker/haproxy
/usr/lib/ocf/resource.d/heartbeat/haproxy
このファイルを保存後、haproxyのリソース定義の際に、タイプを "lsb:" ではなく "ocf:" と指定することでこのエージェントファイルが利用されるようになります。 なお、作成したOCFファイルには実行属性を与えてください。( $ sudo chmod 0755 haproxy )
OCFおよびLSBのスクリプトファイルにどんなものがあるかを確認したいときは、以下のコマンドで確認できます。
HAProxyを経由してアクセスされた場合、squid のログにはクライアントアドレスが HAProxyノードのアドレスしか残りません。これを回避するには、haproxy.cfgの中で "option forwardfor" ステートメントを記述した上で、squid 側でも以下の設定を行う必要があります。
■ /etc/squid/squid.conf
参考:
http://gihyo.jp/admin/serial/01/pacemaker/0002?page=1
http://www.yamikuro.com/wiki/index.php?UNIX%2FHA%2FHeartbeat
http://blog.suz-lab.com/2010/02/lsb.html
ocf作成ガイド
https://github.com/russki/cluster-agents/blob/master/haproxy