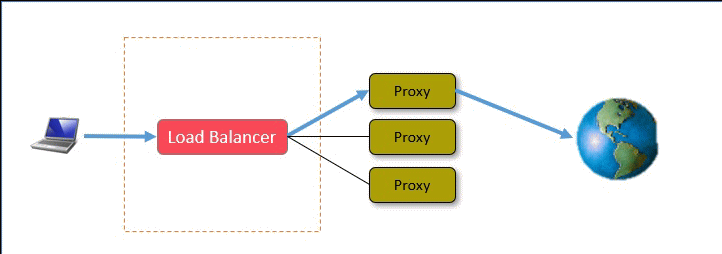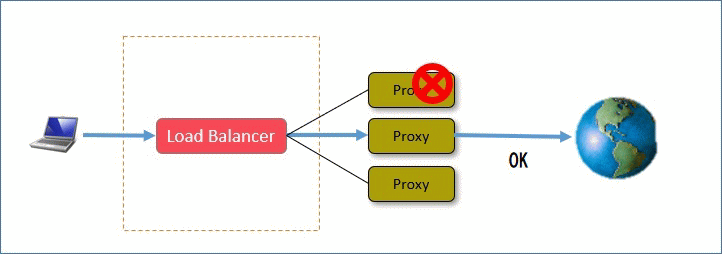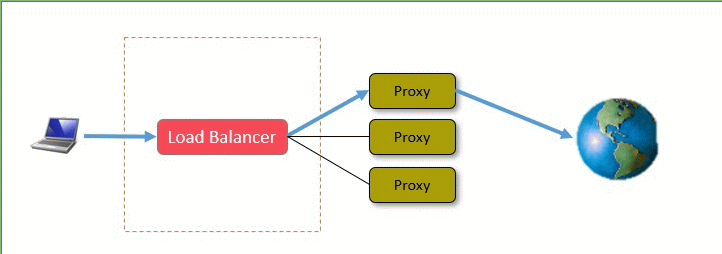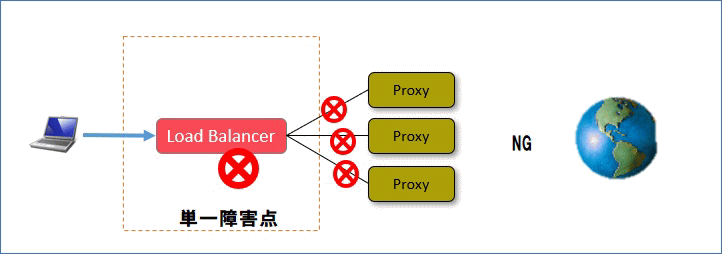
LBを使うことで、WebサーバやProxyを複数台構成にすることでに冗長性を持たせることが可能ですが、LBに障害が発生してしまうとそのままで単一障害点となってしまい、冗長性が無くなってしまうことになります。
この章ではHAProxyを2台構成とするとともの冗長化ソフトであるPacemakerを使ったロバスト化されたHAProxyシステムの構成例を示していきます。
本資料では、Proxyサーバ+HAProxy+Pacemaker+Corosyncという構成を示します。
PacemakerおよびCorosyncは、Linux-HA Projectが開発しているクラスタリングサポートソフトで以前は「Heartbeat」という名前で開発されていました。 Heartbeatのうち、死活監視を受け持つ部分をCorosync、リソース管理を行う部分をPacemakerが受け持つように新たに設計が見直され現在の形となっています。 なお、死活監視部分で従来のHearbeet+Pacemakerという形でHA化も可能ですが、この資料ではCorosync+Pacemakerで説明を行います。
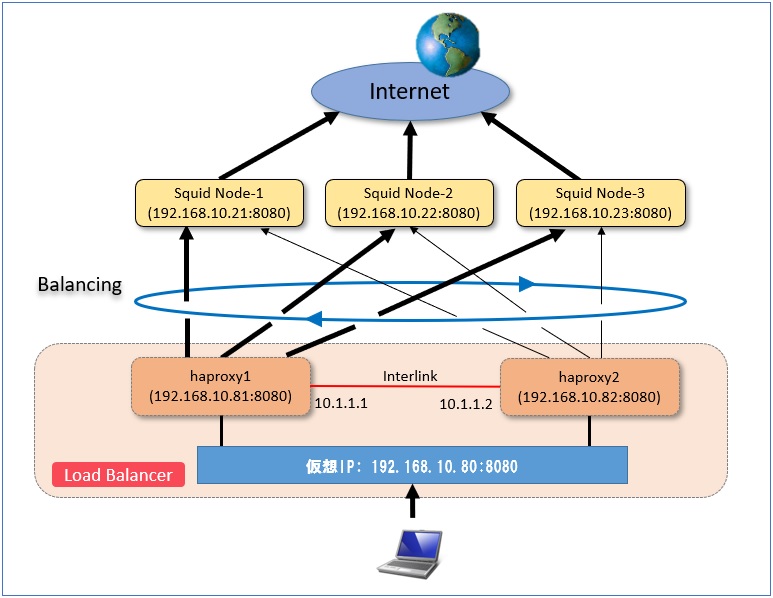
構築環境は図の構成のように、HAProxyサーバを2台構成としてこれを仮想IPアドレスでアクセスさせるようにします。 2台のHAProxyはInterlink接続によって相互に監視しており、障害があった場合にはもう片方のHAProxyサーバに切り替わり処理を継続するようにします。 HAProxyサーバの構成は以下のようになります。
(haproxy1)(haproxy2)
- OS: CentOS 7
- ネットワーク:
- (eth0) 192.168.10.81/24
- (eth1) 10.1.1.1/24
- OS: CentOS 7
- ネットワーク:
- (eth0) 192.168.10.82/24
- (eth1) 10.1.1.2/24
Interlink用のインターフェース(10.1.1.x)はデータ用(192.168.10.x)と一緒のインターフェースにすることも可能ですが、その場合データ用インターフェースに思わぬトラフィックがかかった場合にハートビートを認識できなくなり、相互に相手のHAProxyサーバが不調と判断されて思わぬ挙動にかる可能性があります。
Interlinkは可能な限りデータ用のインターフェースとは違うインターフェースで構成してください。
HAProxyの設定完了後にHA化のためのソフトをインストールします。 インストールは両方のHAProxyサーバで行います。
CentOSを使う場合には、NetworkManager-config-serverをインストールします。(参照) RedHatでは、既にインストールされている筈なので不要です。
# yum install -y NetworkManager-config-server
# systemctl restart NetworkManager
CentOSやDebianには、標準パッケージとしてPacemakerやCorosyncが用意されていますが、一部利用できない機能があるので、Linux-HAプロジェクトのリポジトリを追加して、こちらからソフトをインストールするようにします。
まず、https://ja.osdn.net/projects/linux-ha/ にアクセスして、リポジトリリストのパッケージ( pacemaker-repo-1.1.19-1.1.el7.x86_64.rpm)をダウンロードしてきます。
ダウンロードしたrpmファイルをインストールします。
# rpm -iv pacemaker-repo-1.1.19-1.1.el7.x86_64.rpm
またリポジトリの追加後、追加したリポジトリでは無くOS標準のパッケージからPacemaker、Corosync関連のソフトがインストールされないようにする為に以下の除外設定を /etc/yum.repos.d/CentOS-Base.repo ファイルにしておきます。
[base]
...
exclude=pacemaker* corosync* resource-agents* crmsh* cluster-glue* libqb*
fence-agents* pcs*
[updates]
...
exclude=pacemaker* corosync* resource-agents* crmsh* cluster-glue* libqb*
fence-agents* pcs*
ファイルの編集が終わったら、以下のコマンドを実行します。
# yum update
クラスタリングサポートツールをインストールします。 なお、Pacemaker制御コマンドとしては、"crm"または"pcs"のどちらか一方だけあれば十分です。ここでは両方のコマンドツールをインストールしていますが、説明ではcrmを使います。
# yum install pacemaker-all corosync crmsh pcs
# systemctl enable pacemaker
# systemctl enable corosync
# systemctl enable pcsd # --- pcsは使わないので指定は不要
なお、Pacemaker/Corosyncを使うにあたりファイアーウォールを動かしている場合には、利用ポート許可設定が必要ですので、以下のコマンドを実行します。
# firewall-cmd --add-service=high-availability --permanent
success
# firewall-cmd --reload
(1). OCFファイルの入手
Pacemakerでリソース管理を行う場合、リソースとしてHAProxyのプラクラムを監視・起動/停止するスクリプトファイルが必要です。https://github.com/russki/cluster-agents/blob/master/haproxy にこのスクリプトファイルがあるのでこれをコピーして /usr/lib/ocf/resource.d/heartbeat/haproxy というファイルで作成します。
(2). 実行権の付与
作成した /usr/lib/ocf/resource.d/heartbeat/haproxy ファイルに実行権を付与します。
# chmod +x /usr/lib/ocf/resource.d/heartbeat/haproxy
それぞれのHAProxyサーバで、Interlinkの接続で相手の状態を監視させるための設定を行います。/etc/corosync/corosync.conf ファイルを次のように準備します。
(1). /etc/corosync/corosync.conf の用意
# cp /etc/corosync/corosync.conf.example /etc/corosync/corosync.conf
(2). /etc/corosync/corosync.conf を編集します。
それぞれのHAProxyサーバの /etc/corosync/corosync.conf を以下のように編集します。
totem {
version: 2
cluster_name: HAcluster # --- クラスター名として適当な名前を付けます。
crypto_cipher: none
crypto_hash: none
interface {
ringnumber: 0
bindnetaddr: 10.1.1.0 #
interlink に使うネットワークアドレスを指定します。
# mcastaddr: 239.255.1.1
# --- マルチキャストは無効にします。
# mcastport: 5405
ttl: 1
}
}
logging {
fileline: off
to_stderr: no
# to_logfile: yes
to_logfile: no # --- ログファイルはパフォーマンスを優先するため指定しません。
logfile: /var/log/cluster/corosync.log
to_syslog: yes
debug: off
timestamp: on
logger_subsys {
subsys: QUORUM
debug: off
}
}
quorum {
# Enable and configure quorum subsystem (default:
off)
# see also corosync.conf.5 and votequorum.5
provider: corosync_votequorum
expected_votes: 2
two_node: 1
wait_for_all: 1
last_man_standing: 1
auto_tie_breaker: 0
}
nodelist { # HAProxy1とHAProxy2それぞれのインターリンク用IPを指定します。(同じ内容)
node {
ring0_addr: 10.1.1.1
name: haproxy1
nodeid: 11
}
node {
ring0_addr: 10.1.1.2
name: haproxy2
nodeid: 12
}
}
(3). /etc/hosts を編集します。
DNSを使わなくても名前解決ができるように、それぞれのHAProxyサーバの /etc/hosts を以下のように編集します。
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.81 haproxy1 haproxy1.example.jp
192.168.10.82 haproxy2 haproxy2.example.jp
(4). 同期の確認
2台のHAProxyへの設定が完了したら、Corosyncを起動して2台を同期できるようにします。
# systemctl restart corosync
# systemctl status corosync
# systemctl restart pacemaker
# systemctl status pacemaker
それぞれのサービスが起動したら、同期の確認をします。(どちらか片方で実行)
[haproxy1 ~] # crm_mon -1
Stack: corosync
Current DC: haproxy1 (version 1.1.19-1.el7-c3c624e) - partition with quorum # -- haproxy1がマスタとなっている
Last updated: Sun Jun 30 07:24:50 2019
Last change: Sun Jun 30 06:55:26 2019 by hacluster via crmd on haproxy1
2 nodes configured # --- 2台のノードが設定されている
0 resources configured
Online: [ haproxy1 haproxy2 ] # --- haproxy1と haproxy2が同期中である
No active resources
この状態で、haproxy1を再起動すると、マスタがhaproxy2に切り替わることを確認できると思います。
2台で同期ができれいれば、以後の作業をを行います。同期できていない場合には、 /var/log/message の中を調べるか、ファイアーウォール、ネットワーク設定にミスがないかを見直してみてください。
Pacemakerはサーバ上で動いているプロセスや、ネットワークの状態などを監視して、状況によってHA構成の別サーバに制御を渡したり、必要に応じてプロセスを起動する制御を行います。
これにより、例えばHAProxyの動作に異常が発生した場合にフェールオーバーを起こして、別のHAProxyサーバへ切りかえるという事が可能になります。
ここでは今回、
の設定を行います。
- クォーラムの無効化
- STHONITHフェンシングを無効
- 自動でフェールバックさせない
- 仮想IPアドレスの作成
- HAProxyプロセスの監視
- スプリットブレインの抑制(VIPCheckによる)
(1). クォーラムを無効化
2ノードのクラスタ構成なので、クォーラムを使った設定を行わないようにします。
# crm configure property no-quorum-policy="ignore"
(2). STHONITHフェンシング無効化
デバイスが無いのでSTHONITHフェンシングは無効化します。
# crm configure property stonith-enabled="false"
(3). 自動でフェールバックさせない
デフォルトリソースとして障害発生回数として1回目の障害発生からリソースの切り替えを行うようにします。また、ノードがフェールバックした場合にリソースもフェールバックするかを指定します。0の場合にはフェールバック、フェールバックしない場合にはINFINITYとする
# crm configure rsc_defaults resource-stickiness="INFINITY" migration-threshold="1"
(4). 仮想IPの設定
2台のHAproxyサーバが共有する仮想IPアドレスを設定する。 仮想IPはマスターサーバとなっているマシンに割当たり、フェールオーバーが発生することで、他のマシンに切り替わるようになる。
# crm configure primitive vIP_10 ocf:heartbeat:IPaddr2 params ip="192.168.10.80" nic="eth0" cidr_netmask="24" op monitor interval="5s"
なお、仮想IPを割り当てるネットワークインターフェース名(ここでは”eth0”の部分)は、"ip address"コマンドで調べることができる。
(5). HAProxyのリソース設定
HAProxyのリソースを定義します。ここでは、1回障害を発生させたらフェールオーバーして、監視間隔は 5s とします。
# crm configure primitive haproxyd ocf:heartbeat:haproxy meta migration-threshold=1 op monitor interval="5s"
(6). VIPの起動時モニタ用設定
クォーラムを使わない構成なので、Interlinkが切れると、それぞれのHAProxyがマスタになろうとしてしまいます。
そこで、VIP存在シテイル時は、リソースの再作成をしないようにチェッします。その処理としてVIPcheckというエージェントを使います。
# crm configure primitive ckVIP ocf:heartbeat:VIPcheck params target_ip="192.168.10.80"
count="1" wait="5" \
op start interval=0s timeout=60s on-fail=restart start-delay=2s
ERROR: ocf:heartbeat:VIPcheck: got no meta-data, does this RA exist?
ERROR: ocf:heartbeat:VIPcheck: got no meta-data, does this RA exist?
ERROR: ocf:heartbeat:VIPcheck: no such resource agent
Do you still want to commit (y/n)? y
(7). リソースグループの作成
作成したリソース定義の条件が整ったときにリソースを作成するようにするためにリソースグループを作成します。 以下のグループでは、仮想IPが存在しない場合に仮想IPを作成してHAProxyを起動・監視します。
# crm configure group proxyGroup ckVIP vIP_10 haproxyd
以上でリソースの定義は終わりです。 リソース定義の影響で、Pacemakerがおかしな状態で起動されていると考えられるので、一度すべてのHAProxyサーバを終了して、改めて1台づつ起動してください。
crm_monを使って、HAProxyが正常に起動したか確かめます。
# crm_mon -1
Stack: corosync
Current DC: haproxy1 (version 1.1.19-1.el7-c3c624e) - partition with quorum
Last updated: Sun Jun 30 11:44:49 2019
Last change: Sun Jun 30 11:38:17 2019 by root via cibadmin on haproxy1
2 nodes configured
3 resources configured
Online: [ haproxy1 haproxy2 ]
Active resources:
Resource Group: proxyGroup
ckVIP (ocf::heartbeat:VIPcheck): Started haproxy1
vIP_10 (ocf::heartbeat:IPaddr2): Started haproxy1
haproxyd (ocf::heartbeat:haproxy): Started haproxy1